- We can not merge at all, keep all the ISD station IDs as unique and be confident that by creating HadISD we have not degraded any of the data.
- We can merge only in cases where we have specific information (from a national met service, for example) as to the identity of stations. This could also be applied in cases where we have information indicating that a split of a station record would be appropriate
- We can merge (and split) when we have specific information, but also run an automated procedure to identify candidate stations to merge together. An example algorithm has been produced by the International Surface Temperature Initiative databank v1.0 (see description in the paper). However this approach is very likely to introduce some spurious mergers, however careful we are with the algorithm.
When we were thinking of option 3, what we had in mind was something similar to the merging process carried out for HadISD v1.0.0. In that process the merging of short records was carried out before stations were selected, so that lots of short records, once merged, would be long enough to pass the selection criteria. This cross-matching of all 29,000 stations in ISD to obtain a parent-set from which HadISD is drawn will result in some final stations being composed of many short segments. The likelihood that some of these stations will be erroneously merged together is quite high given the automated nature of the build. A subtly different alternative came to mind.
However, what could be done is to select stations on the raw ISD record lengths and reporting intervals, and then using this master-list, see which other stations in the ISD could be merged in to supplement these primary stations. This will not increase the final station list (in fact it will decrease it as there will be stations that have been selected that will be merged together), but should improve the data coverage over time for the final set of merged stations.
 |
| Fig. 1: Flowchart showing envisaged station selection procedure with merging |
Most of the merging process takes place after stations have been selected on the basis of their length of record and their reporting interval, however for specific countries, it occurs before as we have extra and definitive information as to which stations should be merged or split. At the moment there are also stations in the master list which will be selected to merge with other stations in the master list - hence the reduction to 8207.
Selecting stations to Merge
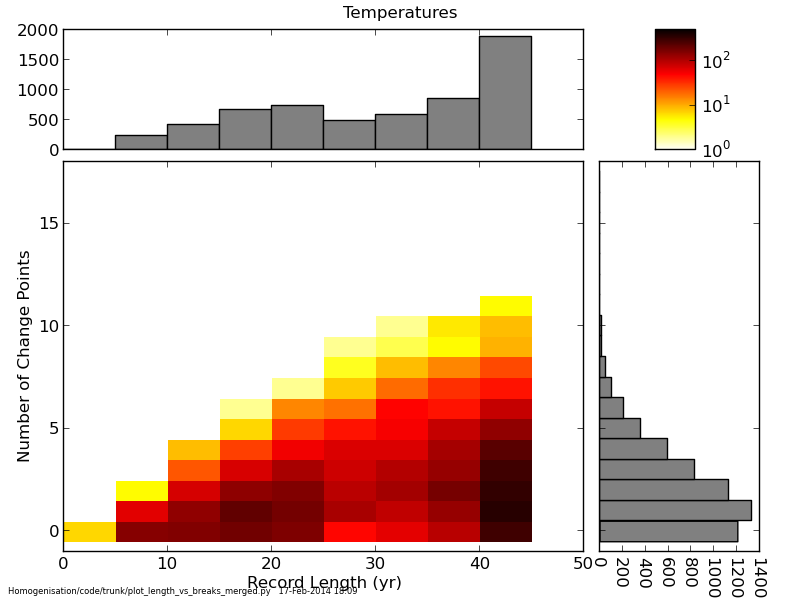
To select stations which are possible merging candidates we so far are using a very simple algorithm. We test the horizontal and vertical separation of the stations and also the similarity of the station names. The distances are mapped to an exponential decay curve, which returns a value between 0 and 1 which we use as a probability. For the horizontal distances, this curve falls to 1/e by 25km, and by 100m for the vertical separation. To calculate the similarity of the station names, we use the Jaccard Index (also used by ISTI), also returning a value between 0 and 1. These three probabilities are multiplied together, and stations where the final value is >0.5 are selected.For an automated system there is no perfect result - there will always be false positives (stations that we shouldn't merge and are distinct) and false negatives (stations that we should merge but do not select to do so). An inspection of the resulting candidates for the UK (where we have more idea of the suitability of merging these candidates) suggests that the values used above are reasonable, with no obvious false positives. The algorithm and thresholds are not yet set in stone, so changes can still occur.
At the current moment in time we find that within the primary station list, 478 stations are similar to others also in the list, reducing the station number to 8207 (including the changes from the German stations outlined below). By cross matching these 8207 stations to the complete ISD database, 2101 will contain data from other station IDs.
 |
| Fig. 2: The effect of the current merging system on the number of stations that report over time. Improvements at the beginning and end of the record are clearly visible. |
Specific Countries - Germany & Canada
For some countries we have specific information about which stations to merge or split (and we hope that we obtain more of these lists as time goes on). Currently we have information about German stations, whose id's start with 09 and 10 in the isd-history.txt files. Here, the last 4 digits of the WMO-ID are important, and some stations have had their records split so that 09abcd and 10abcd are the same station. So we use the selection algorithm to check these station-pairs specifically, and allow them to merge if they pass the same criteria as outlined above.Including this information prior to the station selection criteria results in 8685 stations being selected compared to 8667 before.
For Canada, things are a little more complicated. There are only 1000 WMO-IDs available for Canada, and as a result, stations with different locations have ended up with the same IDs. Thanks to Environment Canada, we have a list of the station moves. In this case we want to split up records so that apparent false mergers are not included in HadISD. We are still working on including this information in the station selection code.
















{kind=link}